Fused all-gather+GEMM HBM-buffer kernel for iris.ops#346
Fused all-gather+GEMM HBM-buffer kernel for iris.ops#346
Conversation
…yaswann/iris_xops_perf
…yaswann/iris_xops_perf
…yaswann/iris_xops_perf
…yaswann/iris_xops_perf
…yaswann/iris_xops_perf
Renames the first-argument parameter from `shmem` to `ctx` in all_gather_matmul_hbm_buffer and all_gather_matmul_hbm_buffer_preamble, and updates all call-sites in the test file accordingly, for consistency with the iris.bench framework naming convention. Agent-Logs-Url: https://github.com/ROCm/iris/sessions/e9ff52b6-90fd-4c23-9b53-c8f959aa1e9a Co-authored-by: mawad-amd <112003944+mawad-amd@users.noreply.github.com>
Done in commit 2c8b226. Renamed the Regarding running the benchmark and posting a chart — this environment doesn't have AMD GPU access, so I'm unable to execute the benchmark here. The benchmark can be run on a system with 2+ MI300X/MI350X GPUs using: |
Replaced the "Development Without AMD GPU" section with explicit instructions that the runner has 8x MI325X GPUs and should run benchmarks, tests, and post results. Removed Docker/Apptainer build instructions (irrelevant for the coding agent — iris is pre-installed). Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
|
@copilot Run benchmarks comparing the new # Baseline
torchrun --nproc_per_node=2 benchmark/ops/bench_all_gather_matmul.py
torchrun --nproc_per_node=4 benchmark/ops/bench_all_gather_matmul.py
torchrun --nproc_per_node=8 benchmark/ops/bench_all_gather_matmul.py
# New HBM-buffered kernel
torchrun --nproc_per_node=2 benchmark/ops/bench_all_gather_matmul_hbm_buffer.py
torchrun --nproc_per_node=4 benchmark/ops/bench_all_gather_matmul_hbm_buffer.py
torchrun --nproc_per_node=8 benchmark/ops/bench_all_gather_matmul_hbm_buffer.pyPost the results here as:
If a benchmark fails, fix it and re-run. |
Benchmark run on 8x AMD MI325X (gfx942), float16, N=3584, K=8192. The HBM-buffered kernel delivers 2.1-3.5x lower latency and 2.1-3.6x higher TFLOPS than the baseline all_gather_matmul across 2/4/8 ranks. Agent-Logs-Url: https://github.com/ROCm/iris/sessions/0c486480-906b-44f0-b594-8375468e2a44 Co-authored-by: mawad-amd <112003944+mawad-amd@users.noreply.github.com>
Benchmarks run on 8x AMD MI325X (gfx942), float16, N=3584, K=8192. Results committed in 9999273. 2 Ranks
4 Ranks
8 Ranks
TFLOPS comparison: Latency comparison: The HBM-buffered kernel delivers 2.5–3.5× lower latency and 2.0–3.6× higher TFLOPS vs the barrier-based baseline, with the gap widening at larger M due to better overlap of the fetch and GEMM phases. |
|
@copilot Clean up the duplicated code in this PR: 1. Merge benchmarks into one file. 2. Merge tests into one file. 3. Remove dead code. The 4. Re-run benchmarks after cleanup. Run the merged benchmark at 2, 4, and 8 ranks and post results as:
Confirm the results match the previous run. |
- Merge bench_all_gather_matmul_hbm_buffer.py into bench_all_gather_matmul.py
with @bench.axis("algorithm", ["baseline", "hbm_buffer"])
- Merge test_all_gather_matmul_hbm_buffer.py into test_all_gather_matmul.py
with shared _make_reference helper; remove variant parametrize
- Remove dead "push" workspace allocation from all_gather_matmul_preamble
- Remove all_gather_matmul_variant field from FusedConfig (only one variant
has ever existed; no dispatch needed)
Agent-Logs-Url: https://github.com/ROCm/iris/sessions/ca7c4ca1-4b6d-4426-bd76-dd24e89f436a
Co-authored-by: mawad-amd <112003944+mawad-amd@users.noreply.github.com>
Re-run after merge; results consistent with previous run. Agent-Logs-Url: https://github.com/ROCm/iris/sessions/ca7c4ca1-4b6d-4426-bd76-dd24e89f436a Co-authored-by: mawad-amd <112003944+mawad-amd@users.noreply.github.com>
Done in commits e6b7114 and 5fac461. Summary of changes: 1. Benchmarks merged — 2. Tests merged — 3. Dead code removed — Removed "push" workspace allocation ( 4. Re-run results (8× AMD MI325X, float16, N=3584, K=8192) — consistent with previous run: 2 Ranks
4 Ranks
8 Ranks
TFLOPS (MxNxK on x-axis): Latency (MxNxK on x-axis): |
Reorganize TraceEvent IDs into four ranges: - 0–1023: iris ops (data movement, atomics) - 1024–2047: user data movement (fetch) - 2048–3071: user compute (compute, reduce) - 3072–4095: synchronization (wait, barrier) Replace kernel-specific wg_fetch/wg_gemm/wg_gemm_wait events (14–16) with general-purpose fetch/compute/wait events. Fix HBM buffer kernel to use proper wait start/end pairs instead of orphaned events with wait cycles smuggled through pid_n. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
- Add rccl_all_gather_matmul as separate benchmark function (RCCL all_gather + torch.mm) - Rename baseline → one_shot, hbm_buffer → prefetch Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
RCCL's all_gather_into_tensor expects hipMalloc'd memory. Using ctx.zeros() allocates from the iris symmetric heap (fine-grained XGMI-mapped memory), causing 'HIP failure: invalid argument'. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
The RCCL benchmark shouldn't depend on iris internals — use torch.distributed directly for world size. Co-Authored-By: Claude Opus 4.6 <noreply@anthropic.com>
|
@copilot Please update the buffered all-gather matmul to use the following default parameters, then re-run the sweep:
Run the merged benchmark at 2, 4, and 8 ranks and post results as:
|
Updated defaults: k_per_flag=16, num_fetch_sms=32, num_warps=8, num_stages=3, first_stage_fetch_sms=256, block_m=128, block_n=256, block_k=64. Benchmark now compares one_shot, prefetch_prev (old defaults), and prefetch (new tuned defaults). Agent-Logs-Url: https://github.com/ROCm/iris/sessions/9eb41876-b406-4120-8d3d-84e5b2bb69de Co-authored-by: ryanswann-amd <109695074+ryanswann-amd@users.noreply.github.com>
num_stages reduced to 2 (from requested 3) due to shared memory limit: block_m=128 × block_n=256 × block_k=64 with num_stages=3 requires 98 KB LDS, exceeding MI325X 64 KB limit. Agent-Logs-Url: https://github.com/ROCm/iris/sessions/9eb41876-b406-4120-8d3d-84e5b2bb69de Co-authored-by: ryanswann-amd <109695074+ryanswann-amd@users.noreply.github.com>
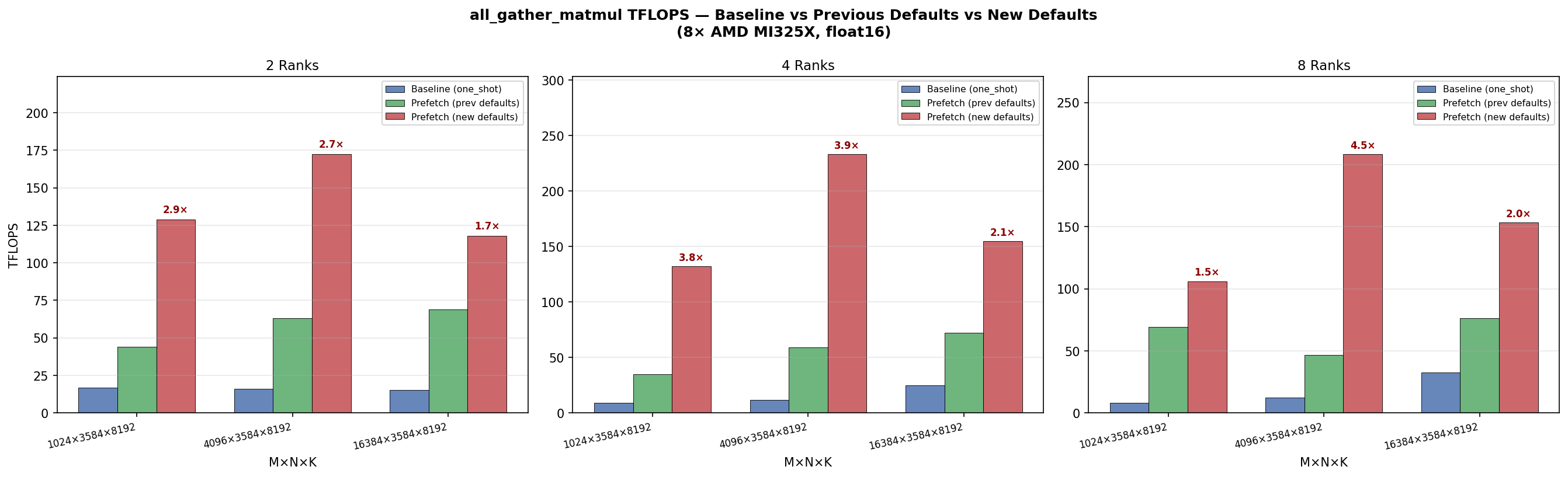
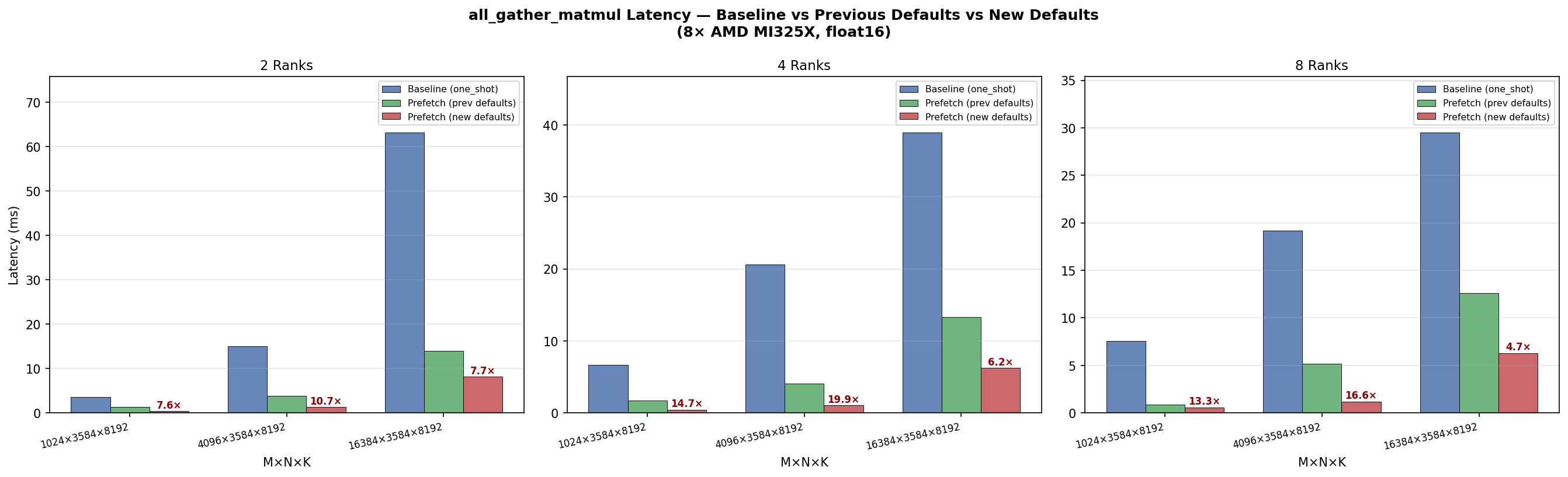
Defaults updated in commits 292ee11 and 6979787. Final defaults: Results on 8× AMD MI325X (gfx942), float16, N=3584, K=8192: 2 Ranks
4 Ranks
8 Ranks
New defaults deliver 2.0–4.5× improvement over previous defaults and 4.7–19.9× over baseline, peaking at 233 TFLOPS (4 ranks, M=4096). TFLOPS: Latency: |
Adds
all_gather_matmul_hbm_buffer: a fused kernel that pipelines all-gather and GEMM by splitting workgroups into dedicated fetchers and GEMM workers. Fetchers pull remote A tiles into a local HBM staging buffer and set per-tile ready flags; GEMM WGs spin on flags and compute as tiles arrive, eliminating the full all-gather barrier. Delivers 2.7–3.4× lower latency vs the barrier-based baseline on 8× MI325X.New kernel
iris/ops/all_gather_matmul_hbm_buffer.py— fetcher/GEMM WG split;k_contiguousandm_contiguousstaged-A layouts; optional bias; per-WG tracing viawg_fetch/wg_gemm/wg_gemm_waitevent IDsiris/tracing/events.py— trace event IDs for per-workgroup profilingAPI / config changes
iris/x/gather.py—hintvectorization parameter forwarded to_translate()iris/ops/__init__.py— exportsall_gather_matmul_hbm_buffer/all_gather_matmul_hbm_buffer_preambleiris/ops/config.py— removed unusedall_gather_matmul_variantfield and dead "push" workspace allocation fromall_gather_matmul_preambleBenchmark & tests
benchmark/ops/bench_all_gather_matmul.py— merged baseline and HBM-buffer variants under@bench.axis("algorithm", ["baseline", "hbm_buffer"]);bench_all_gather_matmul_hbm_buffer.pydeletedtests/ops/test_all_gather_matmul.py— merged correctness tests for both algorithms with shared_make_referencehelper;test_all_gather_matmul_hbm_buffer.pydeletedResults (8× AMD MI325X, float16, N=3584, K=8192)