try combined optimizations#11
Open
bruno-dasilva wants to merge 6 commits into
Open
Conversation
* Optimize LocalModelPiece. Move some cold data to pointers * Apply optimized loop over dirty pieces (only recalculate relative transforms where changed)
Default GCC/Clang builds targeted SSE2 via a wall of -mno-sse3/ssse3/sse4.* flags in the generic MARCH fallback. Replace with -msse4.2, which pulls in SSE3/SSSE3/SSE4.1. AVX/FMA stay banned — FMA contraction changes FP bit patterns and desyncs the deterministic simulation. Minimum x86 CPU is now Nehalem (2008) / Bulldozer (2011). Requires a replay-level sync validation pass before shipping — autovectorization output will differ from prior builds even without FMA. Co-Authored-By: Claude Opus 4.7 (1M context) <noreply@anthropic.com> explicitly list sse4 flags revert part of the code
Change Moves cob engine's internal storage/tracking of threads to a slot pool backed by a std::deque instead of a spring::unordered_map, to eek out some extra performance. There's a hack due to ordering requirements of the existing code but I figure a second PR can clean that up - let's keep this PR focused. Context Some instrumentation of our hash maps found that cob was one of the worst users of our spring::unordered_map, because of how many tombstones it would leave behind in the map (cob has constant thread churn). `spring::unordered_map<int, CCobThread> threadInstances` performance over 5000 late game sim frames was: ``` [HashContainerStats] Top 20 containers by total time (ns/op): type | total-ms | find-hit | find-miss | insert | erase | rehash synced map<int, CCobThread> | 3031.91ms | 130ns | 1360ns | 1292ns | 0ns | 219100ns ``` Changing it to a chained hashmap fixed the find-miss() ns per op (since it didnt have to search the entire array of tombstones) but made the find() worse because it had to chase bucket pointers. So, taking a step back and realizing that nothing really iterates on this and the amount of churn it sees, an object pool is probably a better data structure. So let's try it!
bar-benchmark — PR #11candidate sim trimmed mean (ms) with 95% CI on the relative delta
Per-VM distribution box plots (5) |
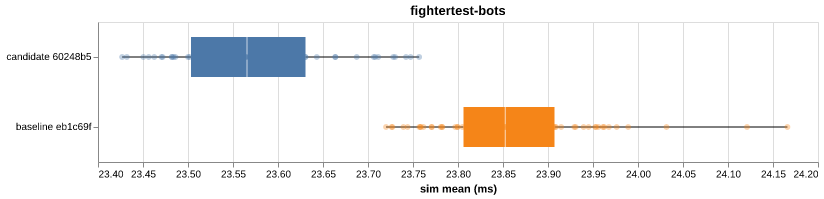
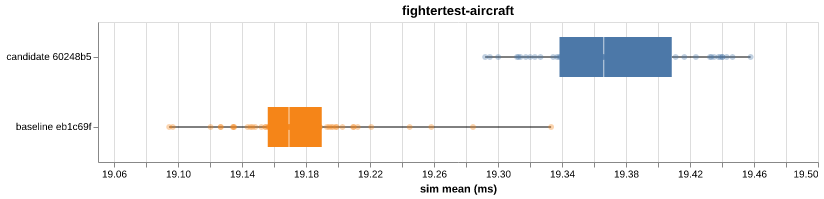
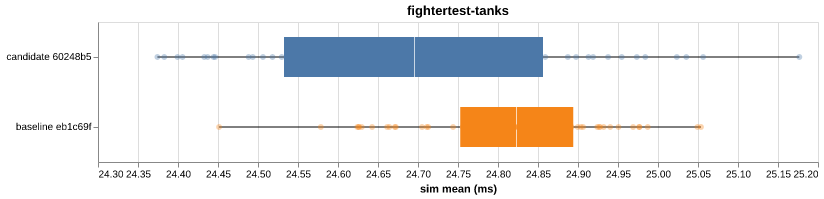
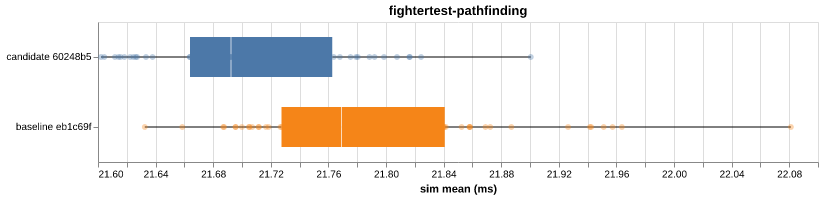

6ae3d38 to
eff5a00
Compare
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
2 participants
Add this suggestion to a batch that can be applied as a single commit.This suggestion is invalid because no changes were made to the code.Suggestions cannot be applied while the pull request is closed.Suggestions cannot be applied while viewing a subset of changes.Only one suggestion per line can be applied in a batch.Add this suggestion to a batch that can be applied as a single commit.Applying suggestions on deleted lines is not supported.You must change the existing code in this line in order to create a valid suggestion.Outdated suggestions cannot be applied.This suggestion has been applied or marked resolved.Suggestions cannot be applied from pending reviews.Suggestions cannot be applied on multi-line comments.Suggestions cannot be applied while the pull request is queued to merge.Suggestion cannot be applied right now. Please check back later.
No description provided.