

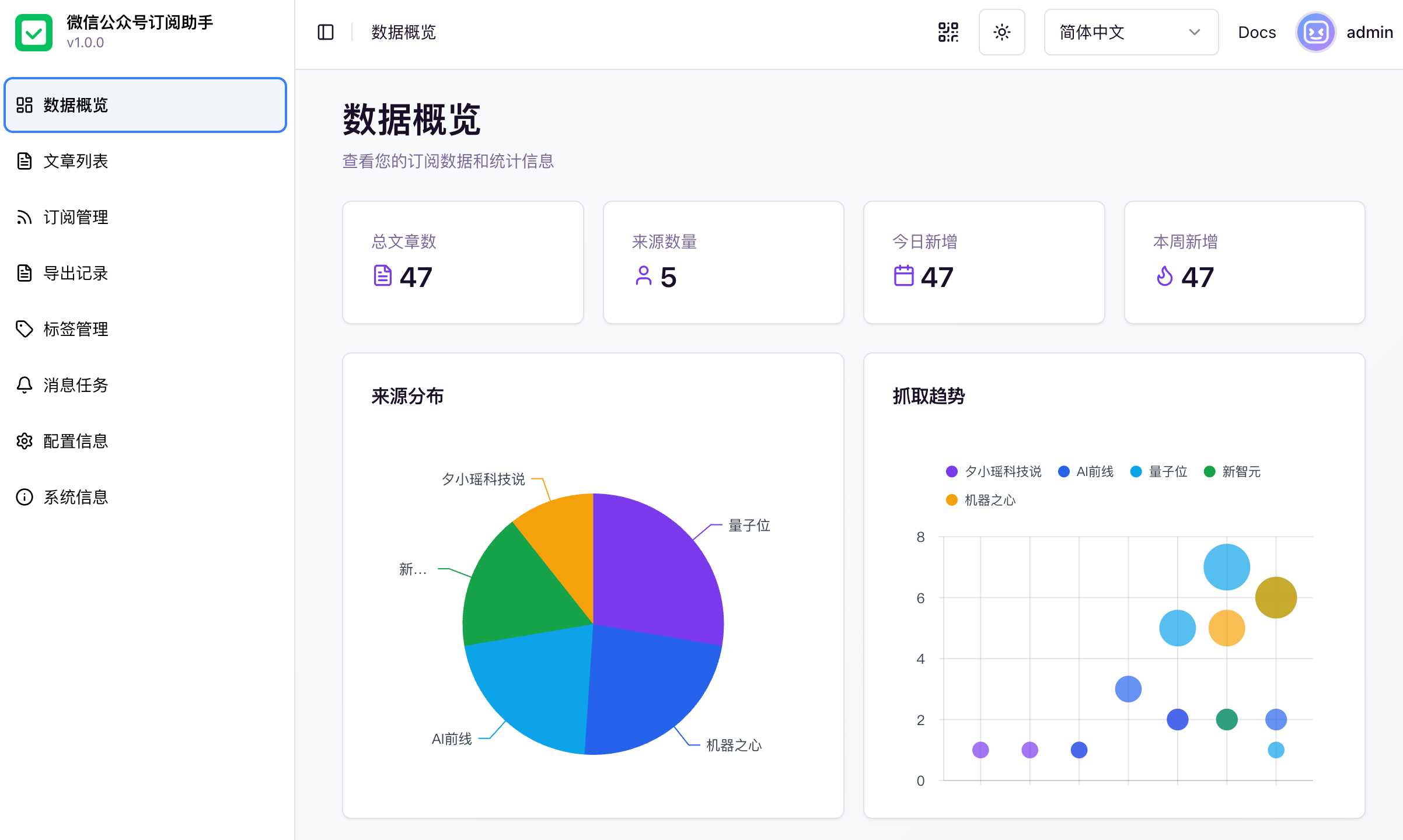
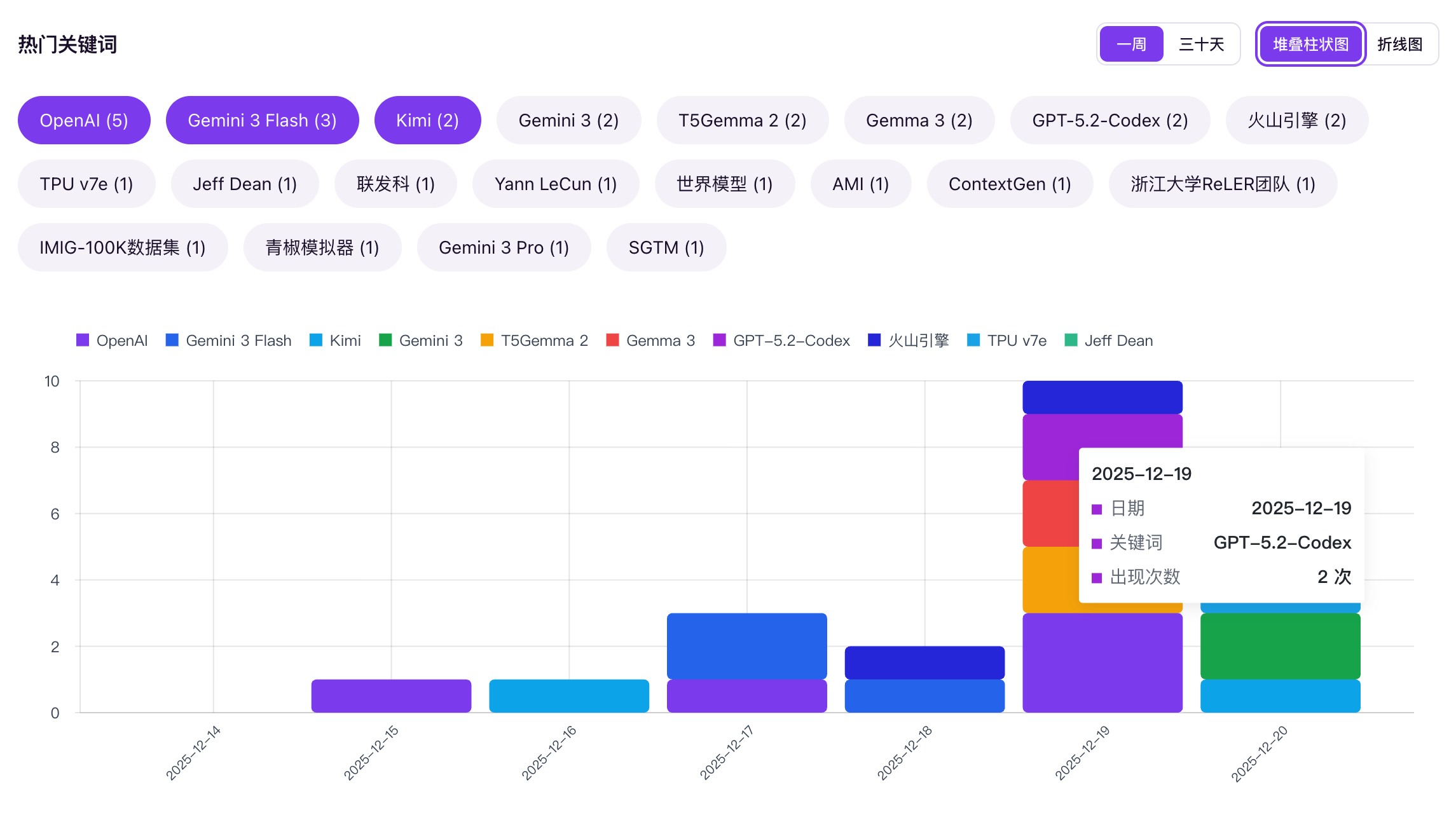
一个功能强大的微信公众号热度分析系统,支持自动采集、标签管理、多格式导出、主题词提取与热度追踪等功能
WeRSS 是一个前后端分离的微信公众号热度分析系统,可以帮助用户将微信公众号文章转换为RSS订阅源,支持自动采集、内容管理、标签分类、多格式导出等功能。
后端:
- FastAPI - 现代化的 Python Web 框架
- SQLAlchemy - Python ORM 框架
- Playwright - 浏览器自动化
- APScheduler - 定时任务调度
前端:
- React 18 - UI 框架
- TypeScript - 类型系统
- Vite - 构建工具
- Tailwind CSS - 实用优先的 CSS 框架
- Radix UI / shadcn/ui - 组件库
- React Router v6 - 路由管理
- Zustand - 状态管理
- Axios - HTTP 客户端
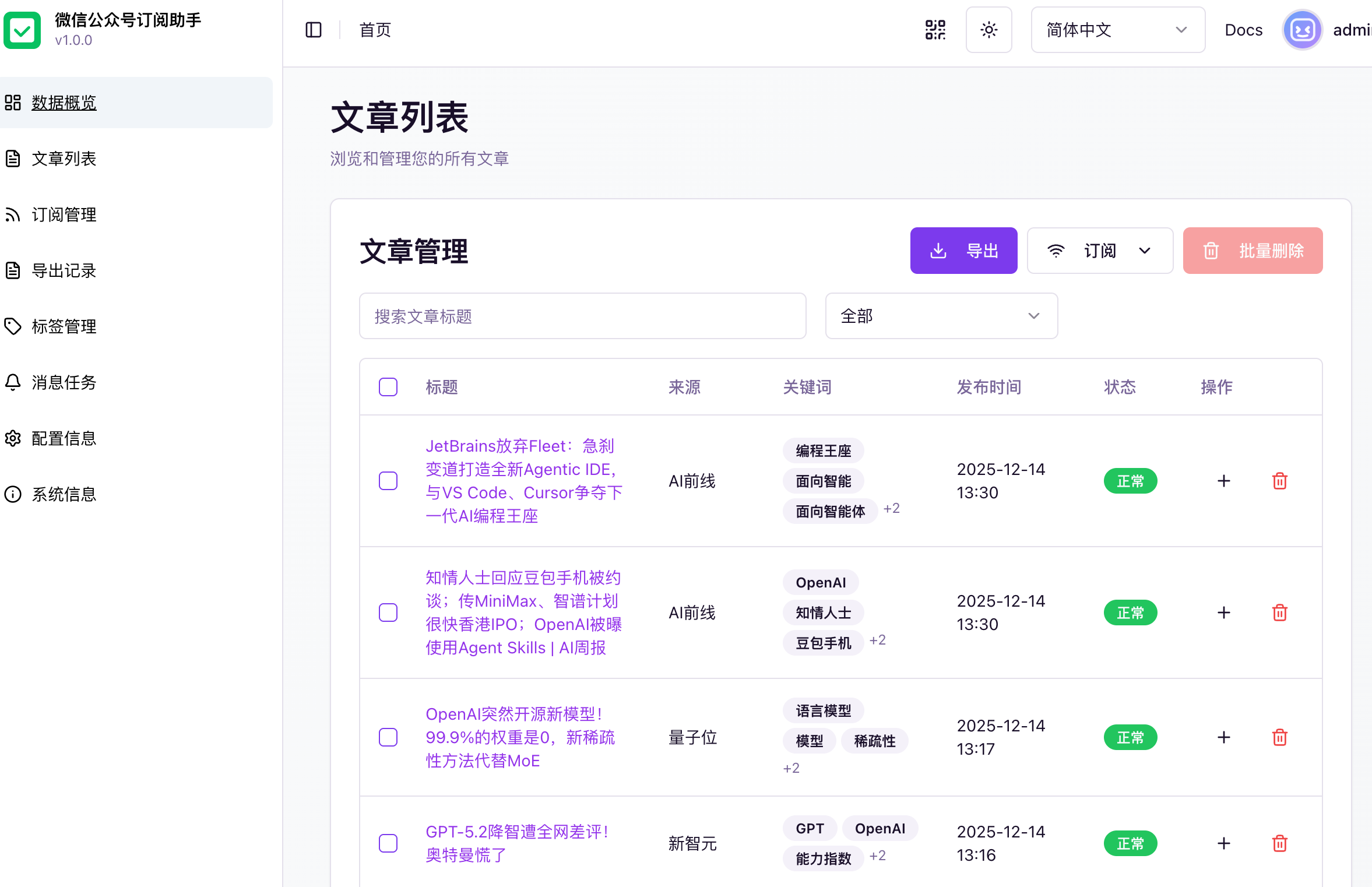
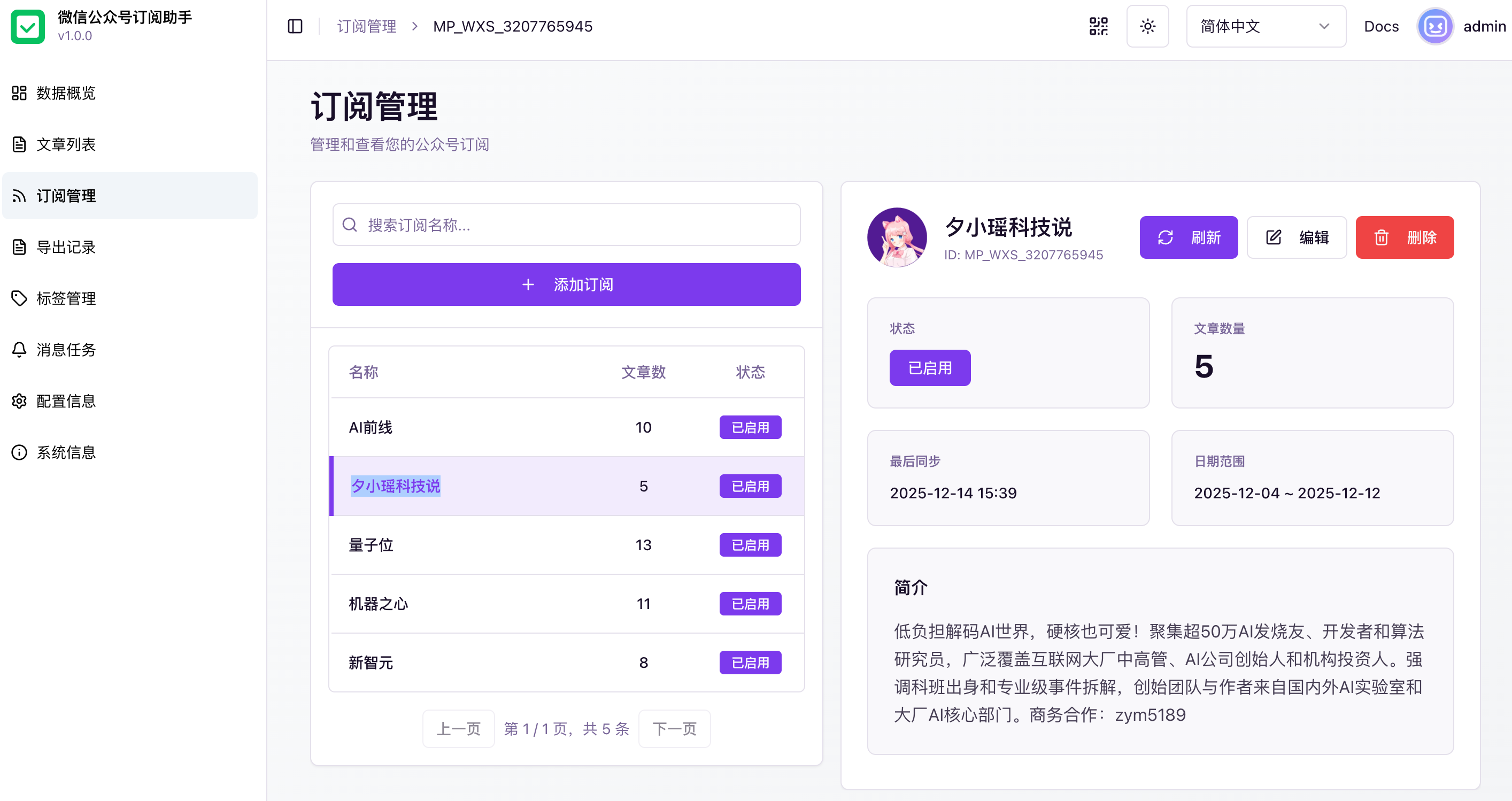
- 🔄 自动采集:支持多种采集模式(web/api/app),自动抓取公众号文章
- 📰 RSS生成:将公众号文章转换为标准RSS订阅源
- 🏷️ 标签管理:支持手动和AI自动标签提取
- 📤 多格式导出:支持PDF、Markdown格式导出
- 🔔 消息通知:支持钉钉、微信、飞书等通知方式
- 🔐 用户认证:完整的用户认证和权限管理
- ⏰ 定时任务:自动执行文章采集和内容更新
- ✅ 自动采集微信公众号文章
- ✅ 支持多种采集模式(web/api/app)
- ✅ 文章内容自动提取和清理
- ✅ 文章搜索和筛选
- ✅ 文章标签分类管理
- ✅ 标准RSS 2.0格式输出
- ✅ 支持全文/摘要模式
- ✅ 自定义RSS标题、描述、封面
- ✅ 支持CDATA格式
- ✅ 分页支持
- ✅ 手动标签管理
- ✅ 自动标签提取(TextRank/KeyBERT/AI)
- TextRank:基于图算法的本地关键词提取,无需外部依赖
- KeyBERT:基于 BERT 的语义关键词提取,支持多语言模型
- AI (OpenAI 兼容):使用 OpenAI 兼容 API(DeepSeek、Qwen3 等)进行智能标签提取,准确度最高
- 优先提取公司名称、产品名称、技术名称等重要实体
- 支持 Qwen3 模型(自动禁用思考功能)
- ✅ 基于公众号的自动标签关联
- ✅ 标签统计和分析
- ✅ 智能标签自动创建
- ✅ PDF导出(需启用)
- ✅ Markdown导出(需启用)
- ✅ 批量导出支持
- ✅ MinIO 对象存储支持
- ✅ 文章图片自动下载和上传
- ✅ 图片URL自动替换为MinIO链接
- ✅ 钉钉Webhook通知
- ✅ 企业微信Webhook通知
- ✅ 飞书Webhook通知
- ✅ 自定义Webhook通知
- ✅ 授权二维码过期通知
- ✅ 消息订阅模板(支持单个公众号和多公众号汇总)
系统支持通过消息任务定时发送公众号文章汇总,支持自定义消息模板。
1. 单个公众号模板
适用于单个公众号的消息推送,模板变量:
{{feed.mp_name}}- 公众号名称{{articles}}- 文章列表{{article.title}}- 文章标题{{article.url}}- 文章链接{{article.publish_time}}- 发布时间{{article.description}}- 文章描述{{article.pic_url}}- 封面图URL
示例模板:
### {{feed.mp_name}} 订阅消息:
{% if articles %}
{% for article in articles %}
- [**{{ article.title }}**]({{article.url}}) ({{ article.publish_time }})
{% endfor %}
{% else %}
- 暂无文章
{% endif %}2. 多个公众号汇总模板(推荐)
适用于汇总多个公众号的文章,模板变量:
{{feeds_with_articles}}- 公众号及文章列表(数组){{item.feed.mp_name}}- 公众号名称{{item.articles}}- 该公众号的文章列表{{total_articles}}- 总文章数{{feeds_count}}- 公众号数量{{task.name}}- 任务名称{{now}}- 当前时间
默认汇总模板:
# 每日订阅汇总
{% for item in feeds_with_articles %}
## {{ item.feed.mp_name }}
{% for article in item.articles %}
- [**{{ article.title }}**]({{ article.url }}){% if article.publish_time %} ({{ article.publish_time }}){% endif %}
{% endfor %}
{% endfor %}
---
共 {{ total_articles }} 篇文章,来自 {{ feeds_count }} 个公众号自定义汇总模板示例:
# 每日订阅汇总
{% for item in feeds_with_articles %}
### {{ item.feed.mp_name }} 订阅消息:
{% for article in item.articles %}
- [**{{ article.title }}**]({{ article.url }}) ({{ article.publish_time }})
{% endfor %}
{% endfor %}
---
共 {{ total_articles }} 篇文章,来自 {{ feeds_count }} 个公众号系统使用 Jinja2 风格的模板语法,支持:
- 变量输出:
{{ variable }} - 条件判断:
{% if condition %}...{% endif %} - 循环遍历:
{% for item in items %}...{% endfor %} - 点号访问:
{{ item.feed.mp_name }}(访问嵌套属性)
- 如果自定义模板中包含
feeds_with_articles变量,系统会使用自定义模板进行汇总 - 如果自定义模板不包含
feeds_with_articles,系统会使用默认的汇总模板 - 单个公众号模板仅适用于单个公众号的消息推送场景
消息模板支持以下通知平台:
- ✅ 飞书:支持富文本(post)和文本格式,自动降级
- ✅ 钉钉:支持 Markdown 格式
- ✅ 企业微信:支持 Markdown 格式
- ✅ 自定义 Webhook:支持 JSON 格式
- 多公众号汇总:使用包含
feeds_with_articles的模板,可以一次性汇总所有公众号的文章 - 单个公众号:使用单个公众号模板,适合针对特定公众号的推送
- 模板测试:在消息任务中可以使用"测试"功能预览模板渲染结果
- Markdown 格式:模板支持 Markdown 语法,可以美化消息格式
- ✅ 用户认证和权限管理
- ✅ 系统配置管理
- ✅ 定时任务管理
- ✅ 系统信息监控
- ✅ 数据统计面板
后端:
- Python: 3.11 或更高版本
- 数据库: SQLite / MySQL / PostgreSQL
- 浏览器: Firefox / Chromium / WebKit(用于Playwright)
前端:
- Node.js: 18+ 或更高版本
- 包管理器: pnpm(推荐)或 npm
# 克隆项目
git clone https://github.com/wang-h/werss.git
cd werss
# 运行一键启动脚本(自动配置环境、安装依赖、启动前后端)
chmod +x start_dev.sh
./start_dev.sh启动后访问:
- 前端界面: http://localhost:5173
- 后台API: http://localhost:8001
- API文档: http://localhost:8001/api/docs
Ubuntu/Debian:
sudo apt-get update
sudo apt-get install -y \
wget git build-essential zlib1g-dev \
libgdbm-dev libnss3-dev libssl-dev libreadline-dev \
libffi-dev libsqlite3-dev procpsmacOS:
brew install python@3.11使用 uv(推荐,更快):
# 安装 uv
curl -LsSf https://astral.sh/uv/install.sh | sh
# 创建虚拟环境
uv venv
# 激活虚拟环境
source .venv/bin/activate # Linux/Mac
# 或
.venv\Scripts\activate # Windows使用传统方式:
python3 -m venv venv
source venv/bin/activate # Linux/Mac
# 或
venv\Scripts\activate # Windows# 使用 uv(推荐)
uv pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 或使用 pip
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simpleplaywright install firefox # 或 webkit, chromium# 复制配置文件模板
cp config.example.yaml config.yaml
# 编辑配置文件(或使用环境变量)
vim config.yaml# 设置环境变量(首次运行需要)
export WERSS_USERNAME=admin
export WERSS_PASSWORD=your_password
# 数据库配置(必须配置 DB 环境变量)
# 使用 SQLite(默认,无需额外配置)
export DB=sqlite:///data/db.db
# 或使用 PostgreSQL(推荐)
export DB=postgresql://admin:12345678@localhost:5432/werss_db
# 注意:使用 PostgreSQL 前需要先启动 PostgreSQL 服务
# 初始化数据库
python main.py -init True# 启动服务(包含定时任务)
python main.py -job True -init False
# 或仅启动API服务(不启动定时任务)
python main.py -job False -init False如果需要单独开发前端:
# 进入前端目录
cd web_ui
# 安装依赖(推荐使用 pnpm)
pnpm install
# 或使用 npm
npm install
# 创建前端环境变量文件
echo "VITE_API_BASE_URL=http://localhost:8001" > .env
# 启动前端开发服务器
pnpm dev
# 或
npm run dev前端服务启动后访问:http://localhost:5173
# 构建镜像(会自动构建前端)
docker build -t werss:latest .
# 运行容器
docker run -d -p 8001:8001 werss:latest
# 访问应用
# 前端界面: http://localhost:8001
# API文档: http://localhost:8001/api/docs# 构建镜像(使用国内镜像源,构建速度更快)
docker build -f Dockerfile.cn -t werss:latest .
# 运行容器
docker run -d -p 8001:8001 werss:latest
# 访问应用
# 前端界面: http://localhost:8001
# API文档: http://localhost:8001/api/docs注意:Docker 镜像已包含前端构建,无需单独启动前端服务。前端和 API 都通过 http://localhost:8001 访问。
docker-compose.dev.yml 提供了完整的本地开发环境,包含 PostgreSQL 数据库、MinIO 对象存储和 WeRSS 应用服务。
特点:
- ✅ 所有服务直接暴露端口,方便本地访问和调试
- ✅ 不需要 Traefik 和域名配置
- ✅ MinIO 使用 HTTP 访问(开发环境)
- ✅ 简化配置,快速启动
- ✅ 数据持久化到本地
./data目录
快速开始:
- 配置环境变量
# 复制环境变量模板文件
cp .env.example .env
# 编辑环境变量(根据实际情况修改)
vim .env主要需要配置的环境变量:
POSTGRES_DB- PostgreSQL 数据库名(默认:werss_db)POSTGRES_USER- PostgreSQL 用户名(默认:admin)POSTGRES_PASSWORD- PostgreSQL 数据库密码DB- 重要:数据库连接字符串,格式:postgresql://用户名:密码@localhost:5432/数据库名- 示例:
DB=postgresql://admin:12345678@localhost:5432/werss_db - 如果不配置
DB,应用会默认使用 SQLite(sqlite:///data/db.db)
- 示例:
WERSS_USERNAME- WeRSS 管理员用户名WERSS_PASSWORD- WeRSS 管理员密码MINIO_ROOT_USER- MinIO 用户名(默认:admin)MINIO_ROOT_PASSWORD- MinIO 管理员密码OPENAI_API_KEY- OpenAI 兼容 API Key(用于 AI 标签提取,可选)
重要提示:
docker-compose.dev.yml已配置自动从.env文件加载环境变量- 必须配置
DB环境变量才能使用 PostgreSQL,否则会使用 SQLite - 如果使用
docker-compose命令,环境变量会在启动时自动加载 - 如果修改了环境变量,需要重启服务:
docker-compose -f docker-compose.dev.yml restart werss
- 启动所有服务
# 启动所有服务(PostgreSQL、MinIO、WeRSS)
docker-compose -f docker-compose.dev.yml up -d
# 查看所有服务状态
docker-compose -f docker-compose.dev.yml ps
# 查看日志
docker-compose -f docker-compose.dev.yml logs -f- 访问服务
启动成功后,可以通过以下地址访问:
- WeRSS 前端界面: http://localhost:8001
- WeRSS API 文档: http://localhost:8001/api/docs
- PostgreSQL 数据库: localhost:5432
- 数据库名:
werss_db(或POSTGRES_DB配置的值) - 用户名:
admin(或POSTGRES_USER配置的值) - 密码: 环境变量中配置的
POSTGRES_PASSWORD - 注意:确保在
.env文件中配置了DB环境变量,格式:DB=postgresql://用户名:密码@localhost:5432/数据库名
- 数据库名:
- MinIO 控制台: http://localhost:9001
- 用户名:
admin(或MINIO_ROOT_USER配置的值) - 密码: 环境变量中配置的
MINIO_ROOT_PASSWORD
- 用户名:
- MinIO API: http://localhost:9000
- 常用操作
# 停止所有服务
docker-compose -f docker-compose.dev.yml down
# 停止并删除数据卷(注意:会删除所有数据)
docker-compose -f docker-compose.dev.yml down -v
# 重启单个服务
docker-compose -f docker-compose.dev.yml restart werss
# 查看特定服务的日志
docker-compose -f docker-compose.dev.yml logs -f werss
docker-compose -f docker-compose.dev.yml logs -f postgres
docker-compose -f docker-compose.dev.yml logs -f minio
# 进入容器执行命令
docker-compose -f docker-compose.dev.yml exec werss bash
docker-compose -f docker-compose.dev.yml exec postgres psql -U admin -d werss_db
# 重新构建并启动(代码更新后)
docker-compose -f docker-compose.dev.yml up -d --build- 数据目录说明
开发环境的数据会保存在项目根目录的 ./data 目录下:
data/
├── postgres-data-dev/ # PostgreSQL 数据文件
├── minio-data-dev/ # MinIO 数据文件
└── werss-data/ # WeRSS 应用数据
├── cache/ # 缓存目录
├── pdf/ # PDF 导出目录(如果启用)
└── markdown/ # Markdown 导出目录(如果启用)
注意事项:
- 开发环境使用
-dev后缀的数据目录,避免与生产环境冲突 - 数据库配置:必须在
.env文件中配置DB环境变量才能使用 PostgreSQL- 格式:
DB=postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@localhost:5432/${POSTGRES_DB} - 如果不配置
DB,应用会使用 SQLite(sqlite:///data/db.db)
- 格式:
- 首次启动会自动初始化数据库和创建管理员账号
- 如果修改了环境变量,需要重启服务才能生效:
docker-compose -f docker-compose.dev.yml restart - 开发环境默认启用 DEBUG 模式,日志级别为 DEBUG
- MinIO 在开发环境使用 HTTP,生产环境建议使用 HTTPS
故障排查:
# 检查服务健康状态
docker-compose -f docker-compose.dev.yml ps
# 查看服务启动日志
docker-compose -f docker-compose.dev.yml logs werss
# 检查数据库连接
docker-compose -f docker-compose.dev.yml exec postgres pg_isready -U admin
# 检查 MinIO 服务
curl http://localhost:9000/minio/health/live
# 重置环境(删除所有数据并重新启动)
docker-compose -f docker-compose.dev.yml down -v
docker-compose -f docker-compose.dev.yml up -d项目使用 config.yaml 进行配置,首次运行请从模板复制:
cp config.example.yaml config.yaml项目支持通过环境变量覆盖配置文件中的设置,环境变量优先级更高:
# 数据库配置
export DB=postgresql://user:password@localhost:5432/werss_db
# 服务器配置
export PORT=8001
export DEBUG=False
export AUTO_RELOAD=False
# 用户认证(首次运行)
export WERSS_USERNAME=admin
export WERSS_PASSWORD=your_password
# 定时任务
export ENABLE_JOB=True
export THREADS=2
# RSS配置
export RSS_BASE_URL=https://your-domain.com/
export RSS_TITLE=我的RSS订阅
export RSS_DESCRIPTION=微信公众号热度分析系统
# 通知配置
export DINGDING_WEBHOOK=https://oapi.dingtalk.com/robot/send?access_token=xxx
export WECHAT_WEBHOOK=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=xxx
export FEISHU_WEBHOOK=https://open.feishu.cn/open-apis/bot/v2/hook/xxx
# AI标签提取(可选)
export DEEPSEEK_API_KEY=sk-xxx
export DEEPSEEK_BASE_URL=https://api.deepseek.com# SQLite(默认)
db: sqlite:///data/db.db
# PostgreSQL
db: postgresql://username:password@host:5432/database
# MySQL
db: mysql+pymysql://username:password@host:3306/database?charset=utf8mb4rss:
base_url: https://your-domain.com/ # RSS域名地址
local: False # 是否为本地RSS链接
title: 我的RSS订阅 # RSS标题
description: 微信公众号热度分析系统 # RSS描述
full_context: True # 是否显示全文
add_cover: True # 是否添加封面图片
page_size: 30 # RSS分页大小gather:
content: False # 是否采集内容
model: app # 采集模式:web/api/app
content_auto_check: False # 是否自动检查未采集文章
content_auto_interval: 59 # 自动检查间隔(分钟)
browser_type: firefox # 浏览器类型:firefox/edge/webkitarticle_tag:
auto_assign_by_mp: True # 根据公众号自动关联标签
auto_extract: False # 是否自动提取标签
extract_method: ai # 提取方式:textrank/keybert/ai
max_tags: 5 # 最大标签数量
# TextRank 配置
textrank:
allow_pos: n,nz,vn,a # 允许的词性:n(名词)、nz(其他专名)、vn(动名词)、a(形容词)
# KeyBERT 配置
keybert:
model: minishlab/potion-multilingual-128M # 模型名称(推荐多语言模型)
hybrid: True # 是否使用混合方案(结合 TextRank 实体提取)
# AI 提取配置
ai:
auto_create: True # 是否自动创建不存在的标签系统支持使用 OpenAI 兼容的 API 进行智能标签提取,支持 DeepSeek、Qwen3、OpenAI 等多种服务:
openai:
api_key: sk-xxx # API Key(必填,用于 AI 标签提取)
base_url: https://api.deepseek.com # API 地址(DeepSeek 默认)
# 或使用其他服务:
# base_url: https://api.openai.com/v1 # OpenAI
# base_url: https://dashscope.aliyuncs.com/compatible-mode/v1 # Qwen3
model: deepseek-chat # 模型名称(默认)
# 或使用其他模型:
# model: gpt-4o # OpenAI
# model: qwen-plus # Qwen3环境变量配置:
# OpenAI 兼容 API 配置
export OPENAI_API_KEY=sk-xxx
export OPENAI_BASE_URL=https://api.deepseek.com
export OPENAI_MODEL=deepseek-chat
# 标签提取配置
export ARTICLE_TAG_AUTO_EXTRACT=True
export ARTICLE_TAG_EXTRACT_METHOD=ai
export ARTICLE_TAG_MAX_TAGS=5
export ARTICLE_TAG_AI_AUTO_CREATE=True支持的 API 服务:
- DeepSeek:https://api.deepseek.com(推荐,性价比高)
- OpenAI:https://api.openai.com/v1
- Qwen3:https://dashscope.aliyuncs.com/compatible-mode/v1(自动禁用思考功能)
- 其他 OpenAI 兼容的 API 服务
AI 标签提取特性:
- ✅ 优先提取公司名称、产品名称、技术名称等重要实体
- ✅ 智能理解文章上下文,提取最相关的标签
- ✅ 自动过滤通用词汇(如"AI"、"技术"等)
- ✅ 支持 Qwen3 模型(自动禁用思考功能,直接返回结果)
- ✅ 每个标签 2-15 个字,按重要性排序
获取 API Key:
- DeepSeek:访问 DeepSeek 官网 注册并创建 API Key
- OpenAI:访问 OpenAI 官网 注册并创建 API Key
- Qwen3:访问 阿里云 DashScope 注册并创建 API Key
三种提取方式对比:
| 特性 | TextRank | KeyBERT | AI (OpenAI 兼容) |
|---|---|---|---|
| 准确度 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 速度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| 依赖 | 无(内置) | 需要下载模型 | 需要 API Key |
| 成本 | 免费 | 免费 | 按 API 调用计费 |
| 多语言支持 | ✅ 中文 | ✅ 多语言 | ✅ 多语言 |
| 上下文理解 | ❌ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 实体识别 | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐(优先提取公司名称等) |
| 推荐场景 | 快速提取、离线环境 | 平衡准确度和速度 | 高质量标签提取 |
使用建议:
- 开发/测试环境:使用 TextRank,无需配置,速度快
- 生产环境(中等规模):使用 KeyBERT,准确度和速度平衡
- 生产环境(高质量要求):使用 AI(OpenAI 兼容),准确度最高,适合对标签质量要求高的场景
- 推荐使用 DeepSeek(性价比高)或 Qwen3(自动禁用思考功能)
- AI 提取会优先提取公司名称、产品名称等重要实体
minio:
enabled: false # 是否启用MinIO图片上传
endpoint: "localhost:9000" # MinIO服务地址
access_key: "minioadmin" # 访问密钥
secret_key: "minioadmin" # 密钥
bucket: "articles" # 存储桶名称
secure: false # 是否使用HTTPS
public_url: "http://localhost:9000" # 公开访问URL(可选)启用 MinIO 后,文章爬取时会自动下载图片并上传到 MinIO,文章内容中的图片 URL 会被替换为 MinIO 链接。
功能概述: 系统支持三种标签提取方式,可以根据需求选择最适合的方案。
1. TextRank 提取(本地算法)
- 原理:基于图算法的关键词提取,无需外部依赖
- 优点:速度快、无需网络、完全免费
- 缺点:准确度相对较低,主要基于词频和共现关系
- 适用场景:快速提取、离线环境、对准确度要求不高的场景
配置示例:
article_tag:
auto_extract: True
extract_method: textrank
max_tags: 5
textrank:
allow_pos: n,nz,vn,a # 允许的词性2. KeyBERT 提取(语义模型)
- 原理:基于 BERT 的语义相似度计算,提取与文档最相关的关键词
- 优点:准确度较高、支持多语言、可本地运行
- 缺点:首次使用需要下载模型(约 200-500MB)、内存占用较大
- 适用场景:平衡准确度和速度的场景、需要多语言支持
配置示例:
article_tag:
auto_extract: True
extract_method: keybert
max_tags: 5
keybert:
model: minishlab/potion-multilingual-128M # 推荐多语言模型
hybrid: True # 使用混合方案(结合 TextRank)推荐模型:
paraphrase-multilingual-MiniLM-L12-v2:官方推荐多语言模型,准确度最高minishlab/potion-multilingual-128M:轻量级多语言模型,CPU 友好all-MiniLM-L6-v2:英文文档专用,更轻量级
3. AI (OpenAI 兼容) 提取(智能理解)
- 原理:使用 OpenAI 兼容的大语言模型理解文章内容,智能提取标签
- 优点:准确度最高、理解上下文、支持复杂语义、优先提取公司名称等重要实体
- 缺点:需要 API Key、有调用成本、需要网络连接
- 适用场景:高质量标签提取、对准确度要求极高的场景
- 支持的服务:DeepSeek、OpenAI、Qwen3 等 OpenAI 兼容的 API
配置示例:
article_tag:
auto_extract: True
extract_method: ai
max_tags: 5 # 最大标签数量(默认 5)
ai:
auto_create: True # 自动创建不存在的标签
openai:
api_key: sk-xxx # 必填
base_url: https://api.deepseek.com # 或使用其他 OpenAI 兼容服务
model: deepseek-chat # 或使用其他模型(如 gpt-4o、qwen-plus 等)AI 提取工作流程:
- 系统读取文章标题、描述和内容
- 将内容发送到 OpenAI 兼容的 API
- AI 分析文章主题和关键信息,优先提取:
- 公司名称(如:字节跳动、腾讯、OpenAI 等)
- 产品/服务名称(如:ChatGPT、豆包、微信等)
- 技术/工具名称(如:React、TensorFlow 等)
- 人物名称、特定事件、特定领域等
- 返回最相关的标签关键词(默认最多 5 个)
- 系统自动创建标签(如果
auto_create: True) - 将标签关联到文章
Qwen3 模型特殊支持:
- 使用 Qwen3 模型时,系统会自动禁用思考功能
- 确保直接返回 JSON 格式的标签数组,无需额外处理思考过程
性能优化建议:
- 对于大量文章,建议使用 KeyBERT 或 TextRank
- 对于重要文章,使用 AI 提取获得最佳效果
- 可以混合使用:大部分文章用 KeyBERT,重要文章用 AI
更多配置项请参考 config.example.yaml 文件。
启动服务后,可以通过以下地址访问API文档:
- Swagger UI: http://localhost:8001/api/docs
- ReDoc: http://localhost:8001/api/redoc
- OpenAPI Schema: http://localhost:8001/api/openapi.json
POST /api/auth/login- 用户登录POST /api/auth/logout- 用户登出GET /api/auth/me- 获取当前用户信息
GET /api/mps- 获取公众号列表POST /api/mps- 添加公众号PUT /api/mps/{id}- 更新公众号DELETE /api/mps/{id}- 删除公众号
GET /api/articles- 获取文章列表GET /api/articles/{id}- 获取文章详情DELETE /api/articles/{id}- 删除文章
GET /feeds/{mp_id}.xml- 获取公众号RSS订阅源GET /feeds/all.xml- 获取所有文章RSS订阅源
更多API详情请查看Swagger文档。
werss/
├── apis/ # API路由层
│ ├── article.py # 文章相关API
│ ├── auth.py # 认证相关API
│ ├── mps.py # 微信公众号相关API
│ ├── rss.py # RSS相关API
│ └── ...
├── core/ # 核心业务逻辑
│ ├── config.py # 配置管理
│ ├── database.py # 数据库操作
│ ├── wx/ # 微信公众号核心逻辑
│ ├── models/ # 数据模型
│ ├── notice/ # 通知模块
│ └── ...
├── jobs/ # 定时任务
│ ├── article.py # 文章采集任务
│ ├── mps.py # 公众号更新任务
│ └── ...
├── driver/ # 浏览器驱动(Playwright)
├── web_ui/ # 前端React应用
│ ├── src/ # 前端源代码
│ │ ├── api/ # API接口封装
│ │ ├── components/# 组件
│ │ ├── views/ # 页面组件
│ │ └── ...
│ ├── package.json # 前端依赖配置
│ └── vite.config.ts # Vite配置
├── main.py # 应用入口
├── web.py # FastAPI应用定义
├── config.example.yaml # 配置文件模板
└── requirements.txt # Python依赖
详细开发指南请参考:
-
添加新API:
# 在 apis/ 目录下创建新文件 # apis/my_feature.py from fastapi import APIRouter router = APIRouter(prefix="/my-feature", tags=["我的功能"]) @router.get("/") async def my_endpoint(): return {"message": "Hello"} # 在 web.py 中注册路由 from apis.my_feature import router as my_feature_router api_router.include_router(my_feature_router)
-
修改数据库模型:
# 在 core/models/ 下修改模型 # 然后运行迁移 python main.py -init True
-
添加定时任务:
# 在 jobs/ 目录下创建任务文件 # 任务会自动注册
- 遵循 Python PEP 8 代码规范
- 使用类型提示(Type Hints)
- 编写清晰的注释和文档字符串
# 检查端口占用
lsof -i :8001 # Linux/Mac
netstat -ano | findstr :8001 # Windows
# 修改端口
export PORT=8002
python main.py -job True -init False- 检查数据库服务是否启动
- 确认连接字符串格式正确
- 检查数据库用户权限
playwright install firefox
# 或
playwright install chromium# 使用国内镜像
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
# 或使用uv(推荐)
uv pip install -r requirements.txt# 确保脚本有执行权限
chmod +x start.sh start_dev.sh
# 确保数据目录可写
mkdir -p data
chmod 755 data更多问题请查看 开发指南 或提交 Issue。
- FastAPI: Web框架
- SQLAlchemy: ORM框架
- Playwright: 浏览器自动化
- APScheduler: 定时任务调度
- PyJWT: JWT认证
- BeautifulSoup4: HTML解析
- jieba: 中文分词
- KeyBERT: 关键词提取(可选,用于 KeyBERT 标签提取)
- openai: OpenAI 兼容客户端(可选,用于 AI 标签提取,支持 DeepSeek、Qwen3、OpenAI 等)
- psycopg2-binary: PostgreSQL支持
- PyMySQL: MySQL支持
- reportlab: PDF导出支持
- python-docx: Word文档处理
- minio: MinIO 对象存储客户端(用于图片存储)
完整依赖列表请查看 requirements.txt。
欢迎贡献代码!请遵循以下步骤:
- Fork 本项目
- 创建功能分支 (
git checkout -b feature/AmazingFeature) - 提交更改 (
git commit -m 'Add some AmazingFeature') - 推送到分支 (
git push origin feature/AmazingFeature) - 开启 Pull Request
详细贡献指南请查看 CONTRIBUTING.md。
本项目采用 MIT 许可证。详情请查看 LICENSE 文件。
本项目在开发过程中参考和借鉴了以下优秀的开源项目,特此表示感谢:
- we-mp-rss - 微信公众号热度分析系统,提供了核心功能实现的参考
- wewe-rss - 微信公众号RSS订阅工具,提供了架构设计的灵感
- full-stack-fastapi-template - FastAPI 全栈项目模板,提供了前后端分离架构的最佳实践
感谢这些项目的开发者和贡献者们!
如有问题或建议,请通过以下方式联系:
⭐ 如果这个项目对你有帮助,请给个 Star ⭐
Made with ❤️ by Hao